
pytorch学习笔记:优化器
发布时间:2024-06-10 05:57:14 点击量:
优化器的作用:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签。
管理:更新哪些参数
更新:根据一定的优化策略更新参数的值






为了避免一些意外情况的发生,每隔一定的epoch就保存一次网络训练的状态信息,从而可以在意外中断后继续训练。
2.1、单步调试代码观察优化器建立过程
- 首先运行到断点出step into

- 2.进行到SGD初始化函数

- 3.运行到64行step into进入父类optimizer继续初始化

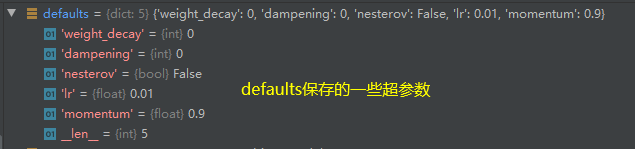

?添加参数后结果如下

网络的构建过程



- 4.step out跳出并完成优化器的创建


- 5.清空梯度
- 6.更新参数
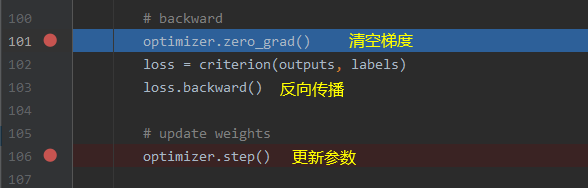
- step():一步更新

- ?zero_gard():清空梯度

- add_param_group():添加参数组

- ?state_dict():获取优化器当前的状态字典

- ?load_state_dict()加载保存的状态字典

假设损失函数如下图所示为y=4*w^2(w为网络的权重)

权重的更新公式为

当学习率为0.5时,由于更新步幅太大造成损失的爆炸

修改学习率为0.2后,损失函数可以稳步的下降,因此学习率的选择非常重要。
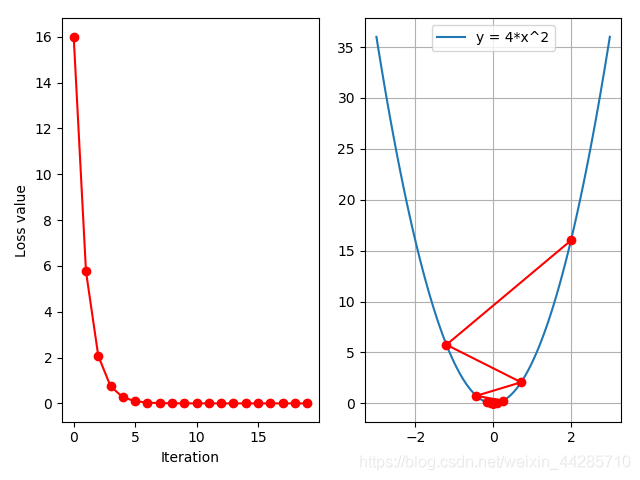
然而面对不同的损失函数和网络,如何选择学习率是一个问题,一般的策略为采取较小的学习率,用时间来换取精度

从上图可以看出,学习率为0.01时,虽然损失下降的比较慢,但最终也能达到不错的效果。
2.4、动量
指数加权平均

各个时刻的权重如下图所示,离当前时刻越远,权重越小,呈指数衰减

参数beta对权重的影响下图所示,可以看出beta的值越小,对过去数据的记忆时间越短。

pytorch中的带动量SGD更新公式

?
3.1、SGD

?3.2、其他优化器

?



?
?
本文为深度之眼Pytorch课程的学习笔记,仅供自己学习使用,如有问题欢迎讨论!关于课程可以扫描下图二维码




